- Data Cleaning-Nghệ Thuật Và Khoa Học Làm Sạch Dữ Liệu: Hướng Dẫn Toàn Diện Từ Checklist Đến Thực Chiến
- Data Profiling in Power Query and PBI
Giới thiệu & Bối cảnh
Sự thật tàn khốc về dữ liệu và Nguyên lý GIGO
Chào mừng bạn đến với Cẩm nang Data Cleaning. Phần này đặt nền móng cho toàn bộ ứng dụng, giải thích lý do tại sao việc chuẩn bị dữ liệu lại là bước quan trọng nhất quyết định sự sống còn của mọi dự án Data Science.
Garbage In, Garbage Out
Dù bạn sử dụng thuật toán Machine Learning hay Deep Learning tiên tiến nhất, nếu dữ liệu đầu vào là “rác” (lỗi, thiếu sót, nhiễu), kết quả dự đoán cũng chỉ là “rác” ngụy trang dưới các con số.
Thời gian làm sạch dữ liệu
Theo Forbes & HBR, các nhà khoa học dữ liệu dành phần lớn thời gian cho việc thu thập và chuẩn bị dữ liệu.
Thời gian xây dựng mô hình
Chỉ một phần nhỏ thời gian thực sự được dùng để chạy thuật toán. Data Cleaning chính là bộ khung tư duy chiến lược.
Trụ cột 1
Loại Bỏ Dữ Liệu Không Liên Quan
Kỹ thuật tối ưu hóa tín hiệu. Phần này giúp bạn xác định và loại bỏ những dữ liệu thừa thãi, nguyên nhân chính gây ra “Lời nguyền của số chiều” (Curse of Dimensionality) làm giảm độ chính xác của mô hình.
“Chỉ khi bạn chắc chắn rằng một phần dữ liệu là không quan trọng, bạn mới có thể loại bỏ nó. Bigger is not always better.”
Loại bỏ theo Cột (Feature Drop)
- ✓ Unique Identifiers: User_ID, Session_ID gây overfitting.
- ✓ Zero Variance: Cột chứa toàn giá trị giống nhau (VD: Toàn bộ là “Vietnam”).
- ✓ Data Leakage: Dữ liệu rò rỉ chứa thông tin biến mục tiêu mà thực tế không có ở thời điểm dự đoán.
Loại bỏ theo Hàng (Observation Drop)
Xóa bỏ các bản ghi không thuộc phạm vi nghiên cứu.
Trụ cột 2
Dữ Liệu Trùng Lặp (Duplicates)
Sự trùng lặp là kẻ thù của tính khách quan. Phần này phân tích tác hại của dữ liệu bị lặp lại và cách phân biệt giữa trùng lặp kỹ thuật và trùng lặp theo logic kinh doanh.
Tác hại
- Gây thiên vị (Bias) cho mô hình do học thuộc quy luật giả.
- Kéo lệch các chỉ số thống kê mô tả (Mean, Median).
Phân loại trong Thực chiến
1. Exact Duplicates (Hoàn toàn)
Toàn bộ các cột giống hệt nhau. Xử lý dễ dàng bằng df.drop_duplicates().
2. Partial Duplicates (Logic kinh doanh)
Ví dụ: KH “Nguyễn Văn A”, SĐT “0901xxx” mua lúc 10:00:01 và 1 bản ghi tương tự lúc 10:00:03. Cột thời gian khác nhau nên không phải Exact, nhưng về logic là lỗi click đúp. Cần xóa dựa trên tập hợp cột (subset).
Trụ cột 3
Chuẩn Hóa Kiểu Dữ Liệu
Máy tính rất khắt khe về định dạng. Phần này tập trung vào việc biến đổi các chuỗi văn bản hỗn loạn thành các định dạng số học và thời gian chuẩn mực để tính toán.
Dữ liệu Số (Number)
Lỗi phổ biến là số bị lưu dưới dạng Chuỗi.
Date & Unix Timestamp
Thời gian là loại dữ liệu phức tạp nhất do Timezone và format.
- Unix Timestamp: Số giây từ 01/01/1970 (VD: 1672531200). Máy tính hiểu, mô hình thì không hiểu chu kỳ.
- Best Practice: Đưa về ISO 8601
YYYY-MM-DD HH:MM:SS. - Feature Engineering: Từ Date trích xuất -> Day_of_Week, Is_Weekend…
Trụ cột 4
Khắc Phục Lỗi Cú Pháp (Syntax Errors)
Đồng nhất ngôn ngữ dữ liệu. Phần này minh họa sức mạnh của biểu đồ Bar Plot trong việc phát hiện các lỗi chính tả (Typos) siêu nhỏ làm phân mảnh dữ liệu Categorical.
Bí quyết: Sức mạnh của “Bar Plot”
Group by to graph a bar plot is the best way. Hãy xem biểu đồ mô phỏng dưới đây cho cột `Thành phố`.
Biểu đồ Trục Y Logarithmic: Phát hiện các Typo li ti làm mô hình hiểu nhầm là 5 thành phố khác nhau.
Các thao tác chuẩn hóa tiêu chuẩn:
Trụ cột 5
Nghệ Thuật Xử Lý Dữ Liệu Khuyết Thiếu
Đây là phần đòi hỏi tư duy phân tích sâu sắc nhất. Dữ liệu bị thiếu hiếm khi hoàn toàn ngẫu nhiên. Hãy tương tác với các tab dưới đây để tìm hiểu 3 hướng tiếp cận cốt lõi.
Phương pháp: Xóa bỏ
Chỉ áp dụng khi tỷ lệ dữ liệu thiếu rất nhỏ (< 5%) và việc thiếu thực sự xảy ra ngẫu nhiên (MCAR - Missing Completely At Random).
Phương pháp: Điền thế / Nội suy
Dự đoán và điền một giá trị hợp lý vào chỗ trống.
- Mean (Trung bình): Cho dữ liệu phân phối chuẩn (not skewed). Dễ bị bóp méo bởi Outliers.
- Median (Trung vị): An toàn, dùng cho dữ liệu bị lệch hoặc có Outliers.
- Random 2 Std Dev: Chọn ngẫu nhiên trong khoảng 2 độ lệch chuẩn để bảo toàn phương sai.
Phương pháp: Gắn cờ (Tư duy chuyên gia)
“Mỗi khi chúng ta xóa hoặc điền dữ liệu, chúng ta đang đánh mất thông tin. Việc gắn cờ là vị cứu tinh.”
Bản thân sự “thiếu” có thể là một manh mối. Ví dụ: Không điền số ĐT cơ quan vì đang thất nghiệp.
If Data = Có -> Phone_is_missing = 0
If Data = Trống -> Phone_is_missing = 1
Kết quả: Mô hình học được tín hiệu từ cột Boolean này trước khi bạn lấp đầy dữ liệu gốc.
Trụ cột 6
Outliers: Kẻ Ngoại Lai
“Outliers are innocent until proven guilty”. Phần này hướng dẫn cách phân biệt lỗi dữ liệu với những sự kiện bất thường có giá trị, sử dụng biểu đồ Scatter để trực quan hóa.
| Bản chất Outlier | Bản án |
|---|---|
|
Lỗi (Error) VD: Tuổi = 250, Nhiệt độ = -500 |
Có Tội (Xóa/Impute) |
|
Sự kiện có thật (Anomaly) VD: Lương CEO x100 nv, GD 2 tỷ lúc 2h sáng. |
Vô Tội (Bắt buộc giữ) |
Công cụ xử lý kỹ thuật:
Minh họa Outlier (Scatter Plot)
Trụ cột 7
Normalization & Scaling
Thu nhỏ tỷ lệ là bước cuối cùng trước khi đưa vào mô hình. Nếu không Scale, thuật toán sẽ bị “mờ mắt” bởi các biến có con số quá lớn (VD: Diện tích 100,000 m2 so với Số phòng ngủ = 2).
Min-Max Scaling
Ép dữ liệu vào khoảng [0, 1]. Tốt cho dữ liệu không có phân phối chuẩn, Neural Networks.
Standardization
Z-score Scaling. Mean = 0, Std = 1. Tốt cho Regression, SVM, dữ liệu ít Outliers.
Robust Scaler
Dùng Median và IQR. Tối ưu khi dữ liệu chứa nhiều Outliers mà bạn đã quyết định giữ lại.
Tổng kết
Workflow & Khuyến Nghị
Data Cleaning là một chu kỳ lặp đòi hỏi sự nhạy bén nghiệp vụ song hành cùng kỹ năng lập trình. Dưới đây là Pipeline tiêu chuẩn giúp bạn tiết kiệm hàng trăm giờ làm việc.
Quy trình Pipeline Tự Động Hóa
Quality Data In, Actionable Insights Out
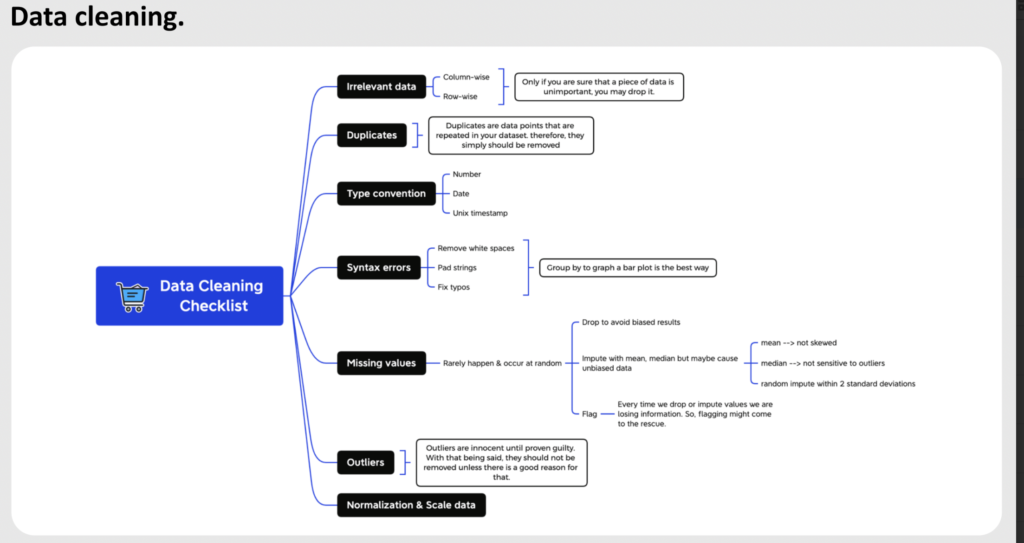
1. Mở bài: Sự thật tàn khốc về dữ liệu và Nguyên lý GIGO
Trong thế giới Khoa học Dữ liệu (Data Science) và Phân tích Dữ liệu (Data Analytics), có một định lý bất di bất dịch được gọi là GIGO (Garbage In, Garbage Out - Rác vào, Rác ra). Dù bạn đang sử dụng những thuật toán Machine Learning tiên tiến nhất như XGBoost, hay các mô hình Deep Learning phức tạp, nếu dữ liệu đầu vào của bạn là "rác" (chứa đầy lỗi, thiếu sót, nhiễu), thì kết quả dự đoán cũng chỉ là "rác" được ngụy trang dưới những con số bóng bẩy.
Theo thống kê của Forbes và Harvard Business Review, các nhà khoa học dữ liệu dành đến 80% thời gian của họ cho việc thu thập, làm sạch và chuẩn bị dữ liệu, và chỉ 20% thời gian để xây dựng mô hình. Điều này minh chứng cho tầm quan trọng cốt lõi của bước Data Cleaning.
Dựa trên "Data Cleaning Checklist", bài viết này sẽ phân tích chuyên sâu 7 trụ cột trong việc làm sạch dữ liệu. Đây không chỉ là một danh sách kiểm tra cơ học, mà là một khung tư duy chiến lược (Strategic Framework) giúp các chuyên gia phân tích đưa ra những quyết định đúng đắn nhất đối với từng điểm dữ liệu.
2. Loại Bỏ Dữ Liệu Không Liên Quan (Irrelevant Data) - Kỹ Thuật Tối Ưu Hóa Tín Hiệu
Nhiệm vụ đầu tiên trong checklist là đối mặt với những dữ liệu không liên quan. Nguyên tắc cốt lõi được nêu ra là: "Chỉ khi bạn chắc chắn rằng một phần dữ liệu là không quan trọng, bạn mới có thể loại bỏ nó." Trong thực tế, dữ liệu càng lớn không có nghĩa là càng tốt (Bigger is not always better). Sự xuất hiện của các dữ liệu thừa thãi sẽ gây ra hiện tượng "Curse of Dimensionality" (Lời nguyền của số chiều), làm tăng nhiễu (noise) và giảm độ chính xác của mô hình.
Chúng ta phân loại việc loại bỏ này theo hai hướng:
2.1. Loại bỏ theo Cột (Column-wise / Feature Drop)
Đây là quá trình loại bỏ các biến (features) không mang lại giá trị dự đoán hoặc phân tích cho bài toán mục tiêu.
- Dữ liệu định danh duy nhất (Unique Identifiers): Các cột như
User_ID,Transaction_ID,Session_IDthường không mang lại giá trị dự đoán vì mỗi hàng có một giá trị riêng biệt, dễ khiến mô hình (đặc biệt là Decision Trees) bị Overfitting. - Dữ liệu có phương sai bằng 0 (Zero Variance Predictors): Một cột mà tất cả các giá trị đều giống nhau (VD: Cột
Countrynhưng toàn bộ dataset đều là "Vietnam") hoàn toàn không chứa thông tin để phân loại hay hồi quy. - Dữ liệu bị rò rỉ (Data Leakage): Đây là lỗi cực kỳ nguy hiểm. Đó là những cột chứa thông tin về biến mục tiêu (Target variable) mà trong thực tế ở thời điểm dự đoán, bạn sẽ không thể có được.
2.2. Loại bỏ theo Hàng (Row-wise / Observation Drop)
Đây là việc xóa bỏ các bản ghi cụ thể không thuộc về phạm vi nghiên cứu (Scope of Analysis).
💡 Case Study: Dự đoán giá bất động sản tại TP.HCM Bạn đang xây dựng mô hình dự đoán giá căn hộ tại TP.HCM. Trong dataset thu thập được, có lẫn lộn một số bản ghi về nhà đất ở Bình Dương, hoặc các loại hình "Đất nông nghiệp". Dù dữ liệu này có đầy đủ các trường thông tin và hoàn toàn sạch sẽ, nó vẫn là Irrelevant Data đối với bài toán của bạn và bắt buộc phải bị loại bỏ theo chiều ngang (Row-wise).
3. Dữ Liệu Trùng Lặp (Duplicates) - Kẻ Thù Của Tính Khách Quan
Sơ đồ định nghĩa rất rõ: "Duplicates là các điểm dữ liệu bị lặp lại trong dataset của bạn. Do đó, chúng đơn giản là nên bị xóa bỏ."
Sự xuất hiện của dữ liệu trùng lặp thường đến từ lỗi hệ thống (System Glitches), lỗi kĩ thuật khi gộp dữ liệu (Data Merging/Joins), hoặc do người dùng submit form nhiều lần.
Tác hại của Duplicates:
- Gây thiên vị (Bias) cho mô hình: Nếu một bản ghi xuất hiện 10 lần, mô hình sẽ học thuộc bản ghi đó và coi đặc điểm của nó là quy luật chung, dẫn đến sai lệch trọng số.
- Làm sai lệch thống kê mô tả: Các chỉ số như Mean, Median sẽ bị kéo lệch.
Phân loại Duplicates trong thực chiến:
- Exact Duplicates (Trùng lặp hoàn toàn): Toàn bộ các cột của Row A giống hệt Row B. Xử lý cực kỳ đơn giản bằng lệnh
df.drop_duplicates()trong Pandas. - Partial Duplicates (Trùng lặp một phần / Trùng lặp theo logic kinh doanh): Đây mới là thách thức.
- Ví dụ: Một khách hàng tên "Nguyễn Văn A", SĐT "0901234567" mua hàng lúc 10:00:01 và một bản ghi khác cùng tên, cùng SĐT mua lúc 10:00:03. Về mặt kỹ thuật (do cột thời gian khác nhau), đây không phải là Exact Duplicate. Nhưng về mặt Business Logic, đây có thể là do lỗi hệ thống thanh toán click đúp. Chuyên gia phân tích phải dùng hàm
subsetđể xóa trùng lặp dựa trên tập hợp cột cụ thể (nhưNamevàPhone).
- Ví dụ: Một khách hàng tên "Nguyễn Văn A", SĐT "0901234567" mua hàng lúc 10:00:01 và một bản ghi khác cùng tên, cùng SĐT mua lúc 10:00:03. Về mặt kỹ thuật (do cột thời gian khác nhau), đây không phải là Exact Duplicate. Nhưng về mặt Business Logic, đây có thể là do lỗi hệ thống thanh toán click đúp. Chuyên gia phân tích phải dùng hàm
4. Chuẩn Hóa Kiểu Dữ Liệu (Type Convention) - Xây Dựng Nền Tảng Kỹ Thuật
Máy tính và các thuật toán toán học rất khắt khe về định dạng. Sơ đồ tư duy nhấn mạnh 3 kiểu dữ liệu cốt lõi cần chuẩn hóa: Number, Date, Unix Timestamp.
4.1. Dữ liệu Số (Number)
Lỗi phổ biến nhất là dữ liệu số bị lưu dưới dạng Chuỗi (String).
- Ví dụ:
"1,000.50","$500", hoặc"25% ". - Hành động: Loại bỏ các ký tự đặc biệt (dấu phẩy, ký hiệu tiền tệ, khoảng trắng) và ép kiểu (Type Casting) về dạng
IntegerhoặcFloat. Nếu không làm điều này, bạn không thể thực hiện bất kỳ phép toán nào (sum, mean, max).
4.2. Dữ liệu Ngày Tháng (Date & Unix Timestamp)
Thời gian là một trong những loại dữ liệu phức tạp nhất do sự khác biệt về định dạng giữa các quốc gia và Timezone.
- Vấn đề: Dataset có thể chứa nhiều định dạng hỗn loạn:
DD/MM/YYYY,MM-DD-YY, hoặc kiểu văn bảnJan 1st, 2023. - Unix Timestamp: Đây là con số biểu diễn số giây đã trôi qua kể từ 00:00:00 UTC ngày 1 tháng 1 năm 1970. (Ví dụ:
1672531200). Dù máy tính đọc rất dễ, nhưng con người và nhiều mô hình không hiểu được ý nghĩa chu kỳ của nó. - Best Practice: Convert tất cả về một chuẩn duy nhất (thường là ISO 8601
YYYY-MM-DD HH:MM:SS). Từ cột Datetime chuẩn này, Data Analyst sẽ thực hiện Feature Engineering để trích xuất ra các cột có giá trị hơn:Day_of_Week,Month,Is_Weekend,Hour_of_Day.
5. Khắc Phục Lỗi Cú Pháp (Syntax Errors) - Đồng Nhất Ngôn Ngữ Dữ Liệu
Dữ liệu dạng Categorical (Phân loại) và Text thường chứa đầy lỗi cú pháp do con người nhập liệu. Sơ đồ gợi ý 3 bước: Remove white spaces (Xóa khoảng trắng thừa), Pad strings (Điền thêm chuỗi), Fix typos (Sửa lỗi chính tả).
5.1. Bí quyết thực chiến: Sức mạnh của "Bar Plot"
Một "Insight" cực kỳ đắt giá từ Mindmap là: "Group by to graph a bar plot is the best way" (Sử dụng biểu đồ cột để nhóm dữ liệu là cách tốt nhất).
Tại sao biểu đồ cột lại là "vũ khí tối thượng" ở đây? Giả sử bạn có cột Thành phố. Bằng mắt thường nhìn hàng triệu dòng, bạn không thể thấy lỗi. Nhưng khi vẽ một Bar Plot đếm số lượng (Value Counts), bạn sẽ thấy:
- Cột cao nhất:
Hồ Chí Minh(50,000 records) - Cột cao thứ 2:
Hà Nội(45,000 records) - Các cột liti, gần sát trục hoành:
ho chi minh(15 records),HCM(20 records),Tp. HCM(5 records),Hô Chi Minh(2 records).
Nhờ Bar Plot, bạn ngay lập tức phát hiện ra các "Typos" (lỗi chính tả) đang làm phân mảnh dữ liệu. Nếu không gộp HCM, ho chi minh... về chuẩn Hồ Chí Minh, mô hình của bạn sẽ coi đây là 5 thành phố hoàn toàn khác nhau.
5.2. Các thao tác chuẩn hóa Text tiêu chuẩn:
- Lower/Upper case: Chuyển tất cả về chữ thường hoặc chữ hoa (
df['city'].str.lower()). - Trim White Space: Xóa khoảng trắng vô tình bị chèn vào đầu/cuối chuỗi (Ví dụ:
" Hanoi "->"Hanoi"). - Regex (Regular Expression): Sử dụng biểu thức chính quy để tìm và thay thế các mẫu sai quy tắc phức tạp.
6. Nghệ Thuật Xử Lý Dữ Liệu Khuyết Thiếu (Missing Values)
Đây là phần phức tạp nhất và đòi hỏi tư duy phân tích sâu sắc nhất. Sơ đồ tư duy đưa ra 3 hướng đi: Drop (Xóa), Impute (Điền thế), và Flag (Gắn cờ).
Trước tiên, cần nhận thức rằng Missing Values hiếm khi xảy ra hoàn toàn ngẫu nhiên. Chúng thường chứa đựng thông tin.
6.1. Phương pháp 1: Drop (Xóa bỏ)
- Khi nào dùng: Chỉ áp dụng khi tỷ lệ dữ liệu thiếu rất nhỏ (ví dụ < 5% tổng dataset) và việc thiếu dữ liệu thực sự xảy ra ngẫu nhiên (MCAR - Missing Completely At Random).
- Cảnh báo: Giống như sơ đồ đã nói, "Drop to avoid biased results" (Xóa để tránh kết quả thiên vị), nhưng nếu bạn xóa quá nhiều, bạn sẽ mất đi những thông tin quý giá.
6.2. Phương pháp 2: Impute (Điền thế / Nội suy)
Đây là quá trình dự đoán và điền một giá trị hợp lý vào chỗ trống.
- Mean (Số trung bình): Áp dụng cho dữ liệu số có phân phối chuẩn (Normal Distribution - not skewed như trong sơ đồ). Nhược điểm: Rất dễ bị bóp méo nếu dữ liệu có Outliers.
- Median (Số trung vị): Phương pháp cực kỳ an toàn và được ưa chuộng cho dữ liệu có phân phối lệch (Skewed data) hoặc có Outliers (not sensitive to outliers). Ví dụ: Điền mức lương thiếu bằng Median sẽ chính xác hơn Mean.
- Random impute within 2 standard deviations: Chọn ngẫu nhiên một giá trị nằm trong khoảng 2 độ lệch chuẩn từ giá trị trung bình. Cách này giúp bảo toàn phương sai của dữ liệu tốt hơn việc chỉ điền một số Mean tĩnh.
6.3. Phương pháp 3: Flagging (Gắn cờ) - Tư duy của Chuyên gia
Sơ đồ có một câu nói cực hay: "Every time we drop or impute values we are losing information. So, flagging might come to the rescue." (Mỗi khi chúng ta xóa hoặc điền dữ liệu, chúng ta đang đánh mất thông tin. Vì vậy, việc gắn cờ có thể là vị cứu tinh).
Bản chất của Flagging: Khi một giá trị bị thiếu, bản thân sự "thiếu" đó có thể là một manh mối (Signal). Ví dụ: Trong đơn vay tín dụng, khách hàng không điền cột "Số điện thoại cơ quan". Tại sao họ không điền? Có thể họ đang thất nghiệp, hoặc làm nghề tự do. Nếu bạn dùng Impute điền bừa một số vào đó, bạn đã vô tình xóa đi manh mối "không có cơ quan".
Cách thực hiện (Missing Indicator): Trước khi bạn Impute (điền Median/Mean) vào cột Phone, bạn tạo thêm một cột Boolean (0 và 1) tên là Phone_is_missing.
- Nếu có số điện thoại gốc ->
Phone_is_missing = 0. - Nếu trống ->
Phone_is_missing = 1(Sau đó mới điền thế cột gốc).
Bằng cách này, mô hình Machine Learning sẽ tự học được: "À, những người có Phone_is_missing = 1 thường có tỷ lệ nợ xấu cao hơn". Bạn vừa giữ được dữ liệu đầy đủ để chạy mô hình, vừa không đánh mất tín hiệu từ việc khuyết thiếu.
7. Outliers: Kẻ Ngoại Lai "Vô Tội Cho Đến Khi Bị Chứng Minh Có Tội"
Định nghĩa kinh điển từ sơ đồ: "Outliers are innocent until proven guilty. With that being said, they should not be removed unless there is a good reason for that." (Outliers vô tội cho đến khi bị chứng minh là có tội. Do đó, không nên xóa chúng trừ khi có lý do chính đáng).
Outliers (Giá trị ngoại lai) là những điểm dữ liệu nằm cách biệt quá xa so với phần lớn dữ liệu còn lại.
7.1. Phân biệt Bản chất của Outlier
Trước khi vội vàng dùng code để xóa Outliers, Data Analyst phải đặt câu hỏi: Đây là Lỗi (Error) hay là Sự kiện bất thường có thật (Anomaly)?
| Loại Outlier | Ví dụ | Cách xử lý (Bản án) |
|---|---|---|
| Lỗi nhập liệu / Lỗi cảm biến (Error) | Tuổi của khách hàng = 250 tuổi. Nhiệt độ phòng = -500 độ C. | Có Tội (Guilty). Xóa bỏ, thay thế bằng Missing Value hoặc Impute lại. |
| Sự kiện có thật (True Anomaly) | Lương của CEO công ty cao gấp 100 lần nhân viên. Giao dịch thẻ tín dụng trị giá 2 tỷ đồng lúc 2h sáng. | Vô Tội (Innocent). Bắt buộc phải giữ lại. Đối với mô hình phát hiện gian lận (Fraud Detection), Outlier này chính là mục tiêu cần dự đoán! |
7.2. Các kỹ thuật phát hiện và xử lý kỹ thuật
Nếu quyết định phải điều chỉnh Outlier để mô hình hồi quy (Linear Regression) không bị kéo lệch đường biểu diễn, chúng ta có các công cụ:
- Z-Score: Xác định điểm nằm ngoài khoảng +/- 3 độ lệch chuẩn (chỉ dùng cho phân phối chuẩn).
- IQR (Interquartile Range): Cắt bỏ các điểm nằm dưới
Q1 - 1.5*IQRvà nằm trênQ3 + 1.5*IQR. Rất mạnh mẽ và hiệu quả qua Boxplot. - Winsorization (Capping): Thay vì xóa, ta "đóng trần" và "lót sàn" dữ liệu. Ví dụ: Tất cả giá trị > Percentile 99% sẽ bị ép gán bằng đúng giá trị ở Percentile 99%. Điều này giúp hạn chế sức mạnh của điểm cực đoan mà không làm mất đi data.
8. Normalization & Scale Data (Chuẩn Hóa và Thu Nhỏ Tỷ Lệ)
Bước cuối cùng trong Checklist, chuẩn bị trực tiếp cho việc đưa dữ liệu vào các thuật toán Machine Learning.
Tại sao phải Scaling? Giả sử bạn dự đoán giá nhà dựa trên 2 biến: Số phòng ngủ (dao động từ 1 đến 5) và Diện tích (dao động từ 50,000 đến 150,000 mét vuông). Các thuật toán dựa trên tính toán khoảng cách (như K-Nearest Neighbors, K-Means Clustering, SVM) hoặc dùng Gradient Descent (như Neural Networks) sẽ bị "mờ mắt" bởi con số quá lớn của Diện tích. Thuật toán sẽ lầm tưởng Diện tích quan trọng gấp vạn lần Số phòng ngủ chỉ vì con số của nó lớn hơn, dẫn đến mô hình bị thiên lệch nghiêm trọng.
Các phương pháp Scale phổ biến:
- Min-Max Scaling (Normalization): Ép toàn bộ dữ liệu vào khoảng
[0, 1]. Tốt cho dữ liệu không có phân phối chuẩn, hoặc áp dụng cho thuật toán Neural Networks, xử lý ảnh.- Công thức:
(X - X_min) / (X_max - X_min)
- Công thức:
- Standardization (Z-score Scaling): Chuyển đổi dữ liệu sao cho Giá trị trung bình (Mean) = 0 và Độ lệch chuẩn (Standard Deviation) = 1. Rất tốt cho các mô hình Regression, SVM, PCA và khi dữ liệu có chứa ít Outliers.
- Công thức:
(X - Mean) / Std
- Công thức:
- Robust Scaler: Sử dụng Median và IQR thay vì Mean và Std. Đây là phương pháp tối ưu nếu dữ liệu của bạn chứa nhiều Outliers mà bạn đã quyết định giữ lại ở bước 7.
9. Kết Luận & Khuyến Nghị Hành Động (Actionable Insights)
Quá trình "Data Cleaning" không bao giờ là một đường thẳng rập khuôn, mà là một chu kỳ lặp đi lặp lại (Iterative process) đòi hỏi sự nhạy bén về nghiệp vụ kinh doanh (Business Domain Knowledge) song hành cùng kỹ năng lập trình (Coding Skills).
Tóm tắt các Nguyên tắc Vàng rút ra từ Checklist:
- Dừng lại và suy nghĩ trước khi Drop: Mọi quyết định xóa cột (Irrelevant), xóa dòng (Row-wise, Nulls), hay xóa Outliers đều phải có lý lẽ rõ ràng. Đừng xóa đi thông tin tiềm năng.
- Luôn Trực quan hóa dữ liệu (Visualize): Bar plot là khắc tinh của lỗi cú pháp (Syntax errors). Boxplot là radar phát hiện Outliers. Histogram giúp quyết định cách Impute (Mean hay Median).
- Tận dụng kỹ thuật Flagging: Biến sự vắng mặt của dữ liệu thành một tính năng (Feature) mới cho mô hình.
- Tôn trọng Outliers: Đừng trừng phạt một điểm dữ liệu chỉ vì nó khác biệt. Hãy tìm hiểu câu chuyện kinh doanh phía sau nó.
Khuyến nghị quy trình làm việc (Workflow): Khi nhận một Dataset mới, hãy viết một Pipeline tuần tự: Xóa Duplicates -> Ép kiểu Type Convention -> Sửa Syntax Errors -> Xử lý Missing Values (Kèm Flagging) -> Phân tích Outliers -> Scaling. Việc tự động hóa quy trình này (sử dụng thư viện như scikit-learn Pipeline) sẽ giúp bạn tiết kiệm hàng trăm giờ đồng hồ trong các dự án thực tế, đảm bảo nguyên lý "Quality Data In, Actionable Insights Out".
Leave a Reply